Phi coefficient
In statistics, the phi coefficient (also referred to as the "mean square contingency coefficient" and denoted by φ or rφ) is a measure of association for two binary variables introduced by Karl Pearson[1]. This measure is similar to the Pearson correlation coefficient in its interpretation. In fact, a Pearson correlation coefficient estimated for two binary variables will return the phi coefficient.[2] The square of the Phi coefficient is related to the chi-squared statistic for a 2×2 contingency table (see Pearson's chi-squared test)[3]
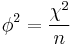
where n is the total number of observations. Two binary variables are considered positively associated if most of the data falls along the diagonal cells. In contrast, two binary variables are considered negatively associated if most of the data falls off the diagonal. If we have a 2×2 table for two random variables x and y
| y = 1 | y = 0 | total | |
| x = 1 | 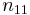 |
 |
 |
| x = 0 | 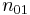 |
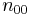 |
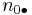 |
| total |  |
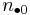 |
 |
where n11, n10, n01, n00, are non-negative "cell cell counts" that sum to n, the total number of observations. The phi coefficient that describes the association of x and y is
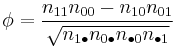
Phi is related to the point-biserial correlation coefficient and Cohen's d and estimates the extent of the relationship between two variables (2 x 2).[4]
Maximum values
Although computationally the Pearson correlation coefficient reduces to the phi coefficient in the 2×2 case, the interpretation of a Pearson correlation coefficient and phi coefficient must be taken cautiously. The Pearson correlation coefficient ranges from −1 to +1, where ±1 indicates perfect agreement or disagreement, and 0 indicates no relationship. The phi coefficient has a maximum value that is determined by the distribution of the two variables. If both have a 50/50 split, values of phi will range from −1 to +1. See Davenport El-Sanhury (1991) [5] for a thorough discussion.
See also
- Contingency table
- Matthews correlation coefficient
- Cramér's V, a similar measure of association between nominal variables.
References
- ^ Cramer, H. 1946. Mathematical Methods of Statistics. Princeton: Princeton University Press, p282 (second paragraph). ISBN 0691080046
- ^ Guilford, J. (1936). Psychometric Methods. New York: McGraw–Hill Book Company, Inc.
- ^ Everitt B.S. (2002) The Cambridge Dictionary of Statistics, CUP. ISBN 0-521-81099-x
- ^ Aaron, B., Kromrey, J. D., & Ferron, J. M. (1998, November). Equating r-based and d-based effect-size indices: Problems with a commonly recommended formula. Paper presented at the annual meeting of the Florida Educational Research Association, Orlando, FL. (ERIC Document Reproduction Service No. ED433353)
- ^ Davenport, E., & El-Sanhury, N. (1991). Phi/Phimax: Review and Synthesis. Educational and Psychological Measurement, 51, 821–828.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||